Scroll down for Interactive Code Environment 👇
Stepping into the next part of my Deep Learning Foundations Series, the spotlight turns to batch processing. This technique transforms neural network efficiency by processing multiple inputs together, sharpening the system’s ability to generalize from training data. With three distinct input vectors guiding us, let’s explore the underlying mechanisms of weight application in batch processing, illuminating neural computation’s path to efficiency.
Exploring Batch Processing
-
Simultaneous Input Processing: This method allows for the simultaneous handling of multiple inputs, improving computational speed. It enables more effective management of large data sets, foundational in current AI training techniques.
-
The Dynamics of Dot Product Calculations: The efficiency of neural networks benefits significantly from the dot product operation, where weight matrices interact with input vector batches. This operation is crucial for parallel input computation.
-
Uniform Weight Application Across Batches: One of the fascinating aspects of batch processing is how a single set of weights is applied consistently across all inputs in a batch. This uniformity ensures that the network learns cohesively from different data points, showcasing the elegance of neural computation.
Walking Through the Code:
This section aims to connect theoretical understanding with tangible application through a Python script example in a two-layer neural network.
Setting the Stage with Initial Parameters:
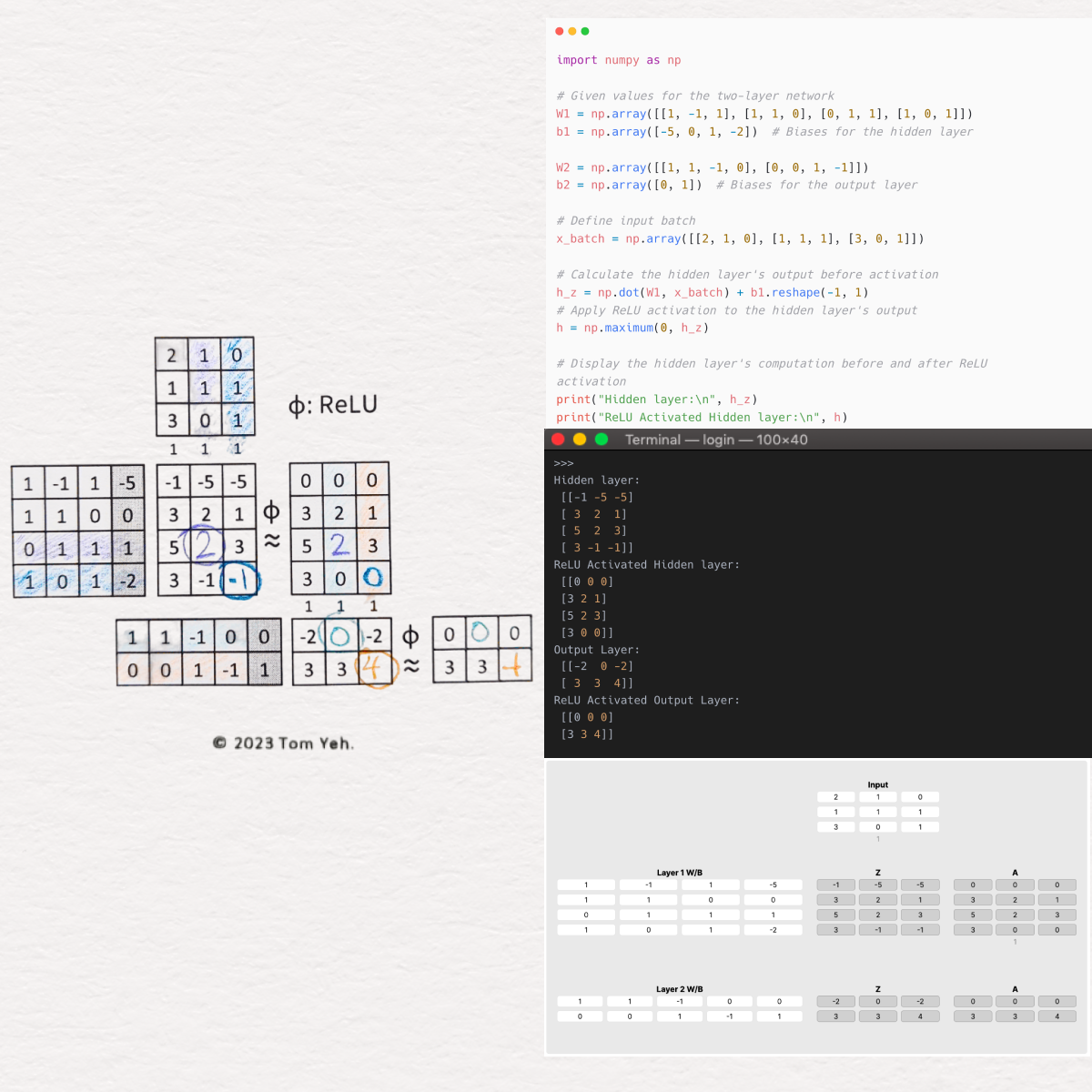
Our journey begins with the definition of the network’s architecture. We’re working with a two-layer neural network, characterized by its weight matrices W1 and W2, and bias vectors b1 and b2. The weights and biases are meticulously chosen to represent the connections and thresholds at each layer of the network, setting the foundation for our computation.
Weights and Biases:
W1andb1govern the transformation from the input layer to the hidden layer, outlining how input signals are weighted and adjusted before activation.W2andb2take charge from the hidden layer to the output layer, determining the final computation leading to the network’s predictions.
Processing the Input Batch:
An essential feature of this example is the use of a batch of inputs, x_batch, consisting of three column vectors made from stacking x1, x2, and x3. This batch processing approach underscores the network’s capacity to handle multiple inputs in parallel, optimizing both time and computational resources.
Hidden Layer Dynamics:
-
Pre-Activation Computation: The first significant step involves calculating the dot product of
W1withx_batch, followed by adding the biasb1. This results inh_z, the pre-activation output of the hidden layer, representing the raw computations awaiting non-linear transformation. -
ReLU Activation: We then apply the ReLU (Rectified Linear Unit) function to
h_z, producingh, the activated output of the hidden layer. ReLU’s role is pivotal, introducing non-linearity into the system by setting all negative values to zero, allowing the network to capture complex patterns beyond linear separability.
Output Layer Revelation:
-
Output Calculation Before Activation: Leveraging the activated hidden layer’s output
h, we perform another round of dot product and bias addition withW2andb2, yieldingy_z. This represents the output layer’s computation before the final activation step. -
Final Activation with ReLU: Applying ReLU once more to
y_zgives usy, the final output of the network. This activated output is crucial for the network’s decision-making process, influencing predictions and actions based on the learned patterns.
The script concludes with a display of both the hidden and output layers’ computations before and after ReLU activation. This visualization not only solidifies our understanding of the network’s internal mechanics but also showcases the transformative power of batch processing and activation functions in shaping the neural computation landscape.
Interactive Code Environment
Original Inspiration
The spark for this exploration came from Dr. Tom Yeh and his educational creations for his courses at the University of Colorado Boulder. His commitment to hands-on learning ignited my interest. Faced with a lack of practical deep learning exercises, he crafted a comprehensive set, ranging from foundational to advanced topics. His enthusiasm for hands-on learning has greatly influenced my journey.
Conclusion
Batch processing stands out as a key factor in the streamlined functioning of neural networks, facilitating swift, coherent learning from extensive datasets. This session’s hands-on example has closed the gap between theoretical concepts and their application, showcasing the streamlined elegance of neural computation. Exciting insights await as we delve deeper into the expansive realm of neural networks and deep learning.
- Last Post: Unraveling Four-Neuron Networks
- Next Post: What is a Multi-Layer Perceptron (MLP)?
LinkedIn Post: Coding by Hand: Batch Processing in Neural Networks

About Jeremy London
Jeremy from Denver: AI/ML engineer with Startup & Lockheed Martin experience, passionate about LLMs & cloud tech. Loves cooking, guitar, & snowboarding. Full Stack AI Engineer by day, Python enthusiast by night. Expert in MLOps, Kubernetes, committed to ethical AI.